Autonomous Navigation of a Mecanum Robot Using DQN in ROS 2
A Reinforcement Learning Approach
Abstract
This project demonstrates the development and implementation of a Deep Q-Network (DQN) a
lgorithm for navigating a Mecanum-wheeled robot in a simulated ROS 2 environment. The objective is to enable the robot to reach a specified target position (e.g.,[1,1]) while avoiding obstacles. Preliminary tests were conducted in TurtleSim
to validate the reinforcement learning (RL) pipeline before transitioning to a Gazebo simulation with the Mecanum robot.
Despite some challenges in saving final training plots for the Mecanum robot, the system showed promising results
in learning and executing collision-free navigation.
Introduction
The primary goal of this project was to apply and refine a DQN-based RL strategy to achieve autonomous navigation in
ROS 2. While standard ROS packages often support classical path-planning methods, they do not natively include reinforcement learning modules. Consequently, the simulation environment and RL pipeline were built from scratch. A Mecanum-wheeled robot was chosen to exploit the advantages of omnidirectional movement, adding complexity and flexibility to the navigation tasks.Tools and Frameworks Used
- ROS 2 Humble: Core framework for the robot simulation and node management.
- Python and PyTorch: Implemented
Methodology
The project was divided into two major phases:
-
Preliminary Testing in TurtleSim:
- Environment Setup: Used TurtleSim for an initial 2D environment. The robot's input was its linear and angular velocity, and the feedback included its pose and velocity.
- Reward System: Devised a reward mechanism with negative rewards proportional to the distance from the goal, and significant penalties for collisions or straying off the defined path.
- Action Execution: Subscribed to the turtle's pose while publishing velocity commands. This phase validated the RL loop and the DQN's ability to converge.
-
Full Implementation in Gazebo:
- Subscriptions and Publications: Subscribed to laser scan and odometry data for obstacle detection and pose estimation. Published velocity commands to control the Mecanum wheels.
- State Representation: Used segmented laser scan data to form a fixed-length state vector representing obstacle proximity.
- Action Space: The DQN output was mapped to Mecanum-specific velocity commands, including lateral, forward/backward, and rotational movements.
DQN Architecture & Training
- Neural Network Configuration: A multi-layer perceptron with two hidden layers (256 units each), outputting Q-values for discrete actions.
- Experience Replay: Implemented via a deque to store state-action-reward transitions, enabling mini-batch updates.
- Epsilon-Greedy Strategy: Balanced exploration (random actions) and exploitation (greedy policy) by decaying epsilon over training episodes.
- Training Process: The agent repeatedly interacted with the environment, collecting experiences and periodically updating the network using PyTorch. The process continued until performance converged or a maximum number of episodes was reached.
Results
TurtleSim: Training plots showed clear improvement over time, with the turtle eventually learning to navigate toward the goal. The reward curve stabilized, confirming that the RL pipeline worked as intended.
Mecanum Robot in Gazebo: Although the final training plots were not successfully saved, the robot exhibited satisfactory performance in reaching the designated goal and avoiding collisions. Preliminary tests validated that the DQN approach could be scaled to a more complex, omnidirectional platform.
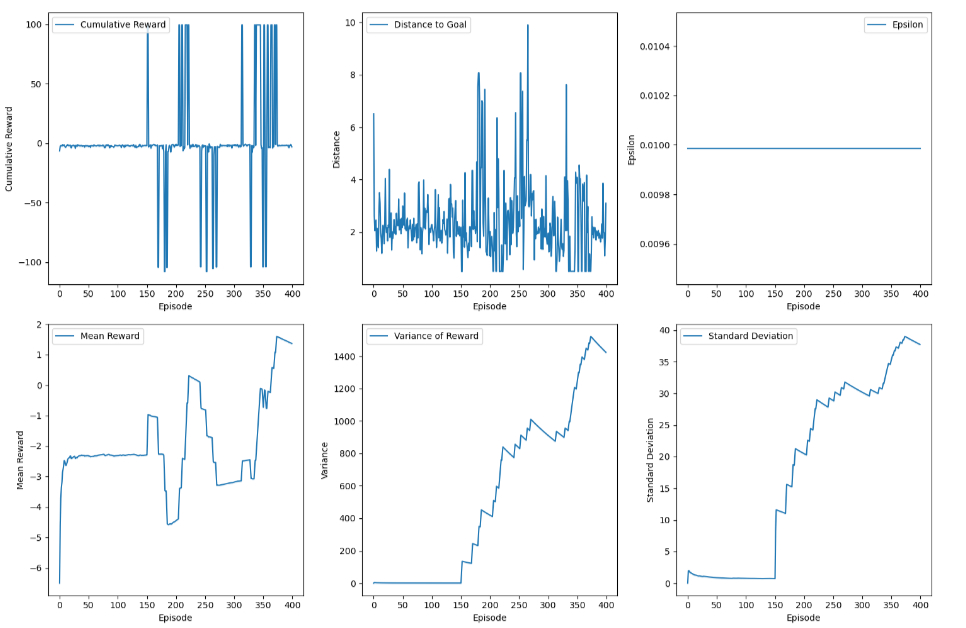
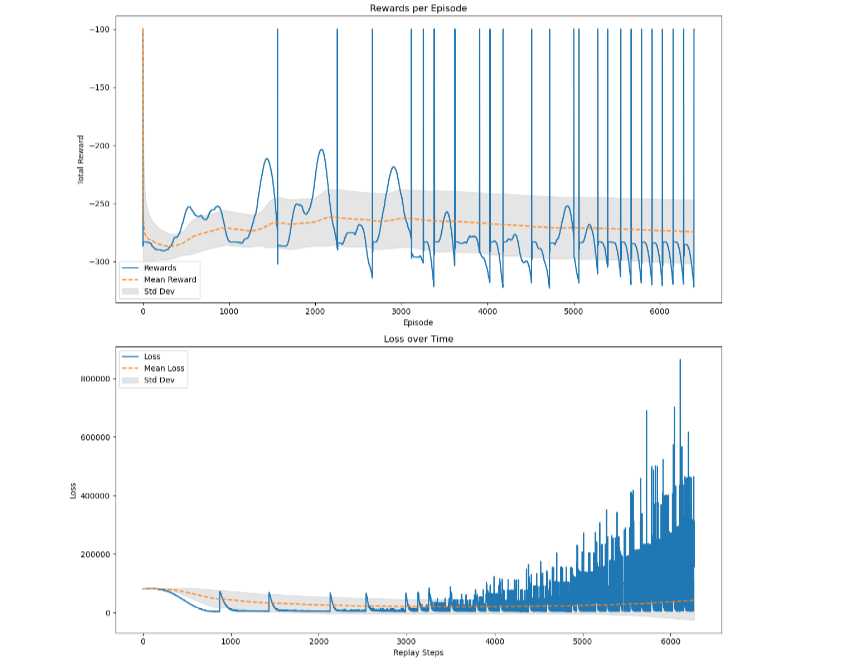
Conclusion and Future Works
This project demonstrated the feasibility of using a DQN algorithm for robotic navigation in ROS 2, covering both a simplified 2D environment (TurtleSim) and a more advanced Mecanum simulation in Gazebo. While the final performance was not fully optimized, it provided a solid foundation for future RL-based robotic systems. Potential improvements include:
- Algorithm Enhancement: Exploring advanced RL methods (e.g., PPO, SAC) for improved convergence and stability.
- Dynamic Obstacles: Introducing moving obstacles to increase navigation complexity.
- Randomized Goals: Generating varied start/goal positions to enhance training robustness.
For More Details or Videos, Visit
Google Photos